OpenAI - Test Classification Prompts#
In this notebook we are going to use the Amazon Review Dataset to test Promptmeteo in the sentiment analysis task
1. Data Preparation - EN - Build sentiment dataset.#
The dataset contains reviews from Amazon in English collected between November 1, 2015 and November 1, 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID and the coarse-grained product category (e.g. ‘books’, ‘appliances’, etc.). The corpus is balanced across stars, so each star rating constitutes 20% of the reviews in each language.
[26]:
import polars as pl
import sys
sys.path.append("..")
data = pl.read_parquet("../data/amazon_reviews_en/amazon_reviews_multi-test.parquet")
sql = pl.SQLContext()
sql.register("data", data)
sentiment_data = (
sql.execute("""
SELECT
review_body as REVIEW,
CASE
WHEN stars=1 THEN 'negative'
WHEN stars=3 THEN 'neutral'
WHEN stars=5 THEN 'positive'
ELSE null
END AS TARGET,
FROM data
WHERE stars!=2 AND stars!=4;
""")
.collect()
.sample(fraction=1.0, shuffle=True, seed=0)
)
train_reviews = sentiment_data.head(100).select("REVIEW").to_series().to_list()
train_targets = sentiment_data.head(100).select("TARGET").to_series().to_list()
test_reviews = sentiment_data.tail(100).select("REVIEW").to_series().to_list()
test_targets = sentiment_data.tail(100).select("TARGET").to_series().to_list()
sentiment_data.head()
[26]:
| REVIEW | TARGET |
|---|---|
| str | str |
| "I reuse my Nes… | "positive" |
| "Fits great kin… | "positive" |
| "Movie freezes … | "negative" |
| "This is my thi… | "positive" |
| "For the money,… | "neutral" |
[3]:
token = "sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
2. EN - Sin entrenamiento#
Prueba 1#
[4]:
prompt = """
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"The texts you will be processing are from the {__DOMAIN__} domain."
PROMPT_LABELS:
"I want you to classify the texts into one of the following categories:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Please provide a step-by-step argument for your answer, explain why you
believe your final choice is justified, and make sure to conclude your
explanation with the name of the class you have selected as the correct
one, in lowercase and without punctuation."
ANSWER_FORMAT:
"In your response, include only the name of the class as a single word, in
lowercase, without punctuation, and without adding any other statements or
words."
"""
[9]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="product reviews",
prompt_labels=["positive", "negative", "neutral"],
selector_k=0,
)
model.task.prompt.read_prompt(prompt)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[9]:
<Axes: >
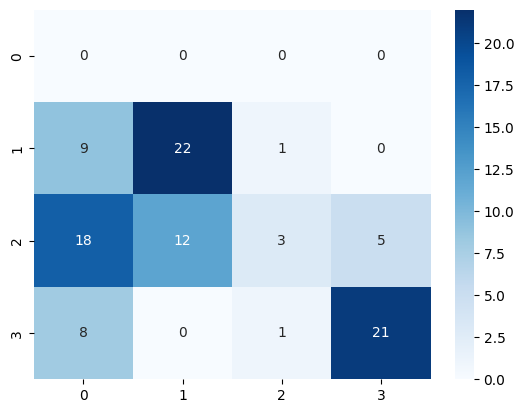
Prueba 2#
[10]:
prompt = """
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"The texts you will be processing are from the {__DOMAIN__} domain."
PROMPT_LABELS:
"I want you to classify the texts into one of the following categories:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Think step by step you answer."
ANSWER_FORMAT:
"In your response, include only the name of the class predicted."
"""
[12]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="product reviews",
prompt_labels=["positive", "negative", "neutral"],
selector_k=0,
)
model.task.prompt.read_prompt(prompt)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[12]:
<Axes: >
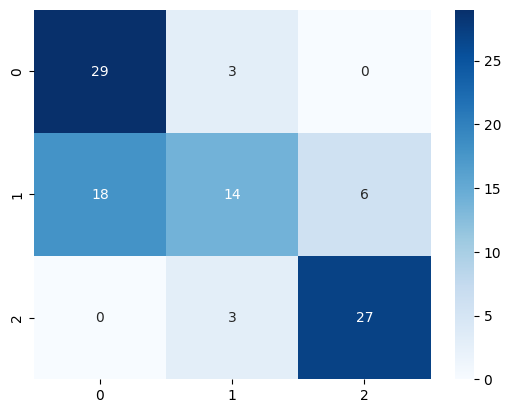
3. EN - Con entrenamiento#
Prueba 1#
[14]:
prompt = """
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"The texts you will be processing are from the {__DOMAIN__} domain."
PROMPT_LABELS:
"I want you to classify the texts into one of the following categories:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Please provide a step-by-step argument for your answer, explain why you
believe your final choice is justified, and make sure to conclude your
explanation with the name of the class you have selected as the correct
one, in lowercase and without punctuation."
ANSWER_FORMAT:
"In your response, include only the name of the class as a single word, in
lowercase, without punctuation, and without adding any other statements or
words."
"""
[15]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
selector_k=10,
)
model.task.prompt.read_prompt(prompt)
model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[15]:
<Axes: >
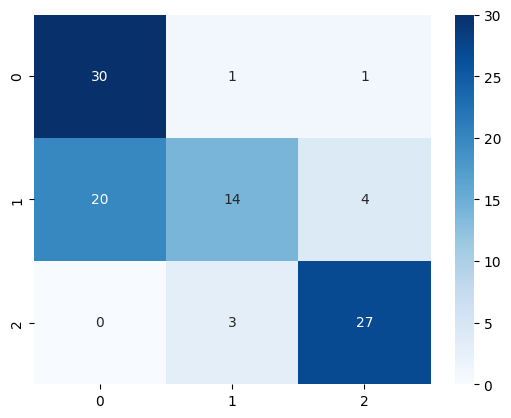
Prueba 2#
[27]:
prompt = """
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"The texts you will be processing are from the {__DOMAIN__} domain."
PROMPT_LABELS:
"I want you to classify the texts into one of the following categories:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Think step by step you answer."
ANSWER_FORMAT:
"In your response, include only the name of the class predicted."
"""
[28]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="product reviews",
prompt_labels=["positive", "negative", "neutral"],
selector_k=20,
)
model.task.prompt.read_prompt(prompt)
model.train(
examples=train_reviews,
annotations=train_targets,
)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[28]:
<Axes: >
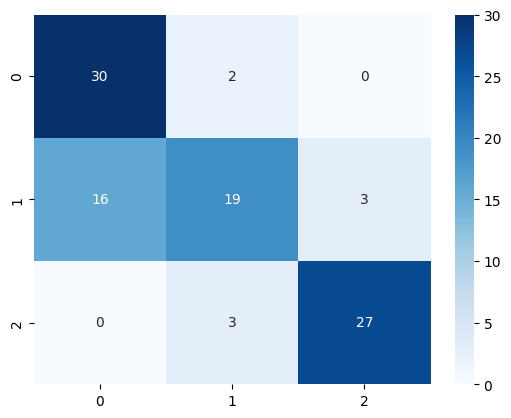
[ ]:
Prueba 3#
[19]:
prompt = """
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
""
PROMPT_LABELS:
""
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
""
ANSWER_FORMAT:
""
"""
[20]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
selector_k=20,
)
model.task.prompt.read_prompt(prompt)
model.train(
examples=train_reviews,
annotations=train_targets,
)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[20]:
<Axes: >
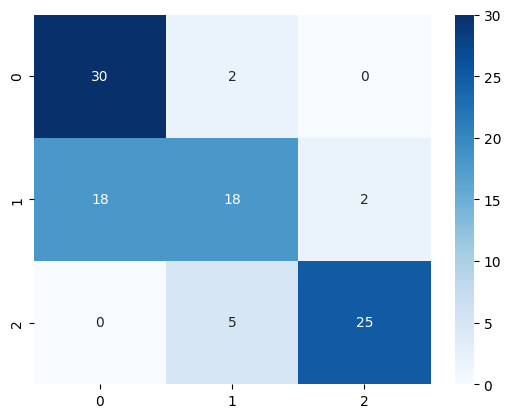
4. Data Preparation - SP - Build sentiment dataset.#
[29]:
import polars as pl
data = pl.read_parquet("../data/amazon_reviews_sp/amazon_reviews_multi-test.parquet")
data.head()
sql = pl.SQLContext()
sql.register("data", data)
sentiment_data = (
sql.execute("""
SELECT
review_body as REVIEW,
CASE
WHEN stars=1 THEN 'negative'
WHEN stars=3 THEN 'neutral'
WHEN stars=5 THEN 'positive'
ELSE null
END AS TARGET,
FROM data
WHERE stars!=2 AND stars!=4;
""")
.collect()
.sample(fraction=1.0, shuffle=True, seed=0)
)
/
train_reviews = sentiment_data.head(100).select("REVIEW").to_series().to_list()
train_targets = sentiment_data.head(100).select("TARGET").to_series().to_list()
test_reviews = sentiment_data.tail(100).select("REVIEW").to_series().to_list()
test_targets = sentiment_data.tail(100).select("TARGET").to_series().to_list()
sentiment_data.head()
[29]:
| REVIEW | TARGET |
|---|---|
| str | str |
| "El filtro de d… | "positive" |
| "Un poquito esc… | "positive" |
| "Para qué decir… | "negative" |
| "Mi hija esta e… | "positive" |
| "Se podría mejo… | "neutral" |
5 SP - Sin Entrenamiento#
Prueba 1#
[49]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"Los textos que vas procesar del ambito de {__DOMAIN__}."
PROMPT_LABELS:
"Quiero que me clasifiques los textos una de las siguientes categorías:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Por favor argumenta tu respuesta paso a paso, explica por qué crees que
está justificada tu elección final, y asegúrate de que acabas tu
explicación con el nombre de la clase que has escogido como la
correcta, en minúscula y sin puntuación."
ANSWER_FORMAT:
"En tu respuesta incluye sólo el nombre de la clase, como una única
palabra, en minúscula, sin puntuación, y sin añadir ninguna otra
afirmación o palabra."
"""
[33]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutral"],
selector_k=0,
)
model.task.prompt.read_prompt(prompt)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[33]:
<Axes: >
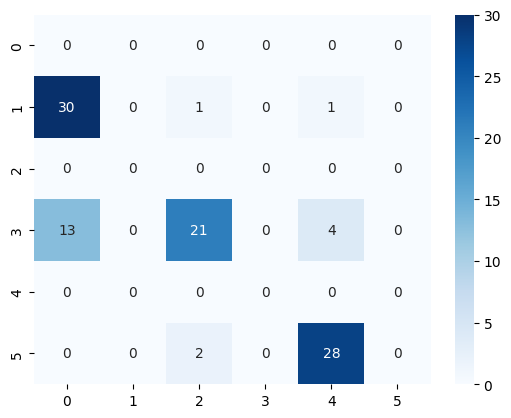
Prueba 2#
[44]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"Los textos que vas procesar del ambito de {__DOMAIN__}."
PROMPT_LABELS:
"Quiero que me clasifiques los textos una de las siguientes categorías:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Argumenta tu respuesta paso a paso."
ANSWER_FORMAT:
"En tu respuesta incluye sólo el nombre de la clase, como una única
respuesta"
"""
[35]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutra"],
selector_k=0,
)
model.task.prompt.read_prompt(prompt)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[35]:
<Axes: >
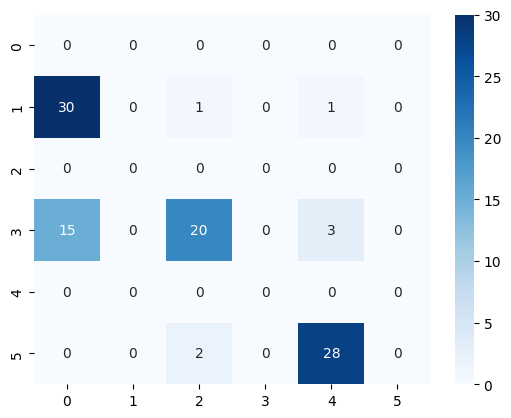
Prueba 3#
[36]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
""
PROMPT_LABELS:
"Quiero que me clasifiques los textos una de las siguientes categorías:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
""
ANSWER_FORMAT:
""
"""
[38]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutra"],
selector_k=0,
)
model.task.prompt.read_prompt(prompt)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[38]:
<Axes: >
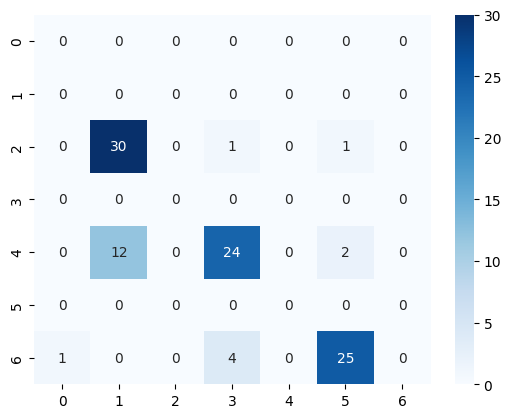
ES - Con entrenamiento#
Prueba 1#
[39]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"Los textos que vas procesar del ambito de {__DOMAIN__}."
PROMPT_LABELS:
"Quiero que me clasifiques los textos una de las siguientes categorías:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Por favor argumenta tu respuesta paso a paso, explica por qué crees que
está justificada tu elección final, y asegúrate de que acabas tu
explicación con el nombre de la clase que has escogido como la
correcta, en minúscula y sin puntuación."
ANSWER_FORMAT:
"En tu respuesta incluye sólo el nombre de la clase, como una única
palabra, en minúscula, sin puntuación, y sin añadir ninguna otra
afirmación o palabra."
"""
[41]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutra"],
selector_k=10,
)
model.task.prompt.read_prompt(prompt)
model.train(
examples=train_reviews,
annotations=train_targets,
)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[41]:
<Axes: >
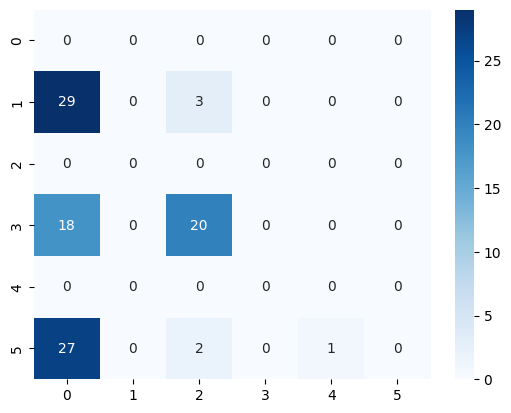
Prueba 2#
[45]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"Los textos que vas procesar del ambito de {__DOMAIN__}."
PROMPT_LABELS:
"Quiero que me clasifiques los textos una de las siguientes categorías:
{__LABELS__}."
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
"Argumenta tu respuesta paso a paso."
ANSWER_FORMAT:
"En tu respuesta incluye sólo el nombre de la clase, como una única
respuesta"
"""
[46]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutra"],
selector_k=10,
)
model.task.prompt.read_prompt(prompt)
model.train(
examples=train_reviews,
annotations=train_targets,
)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[46]:
<Axes: >
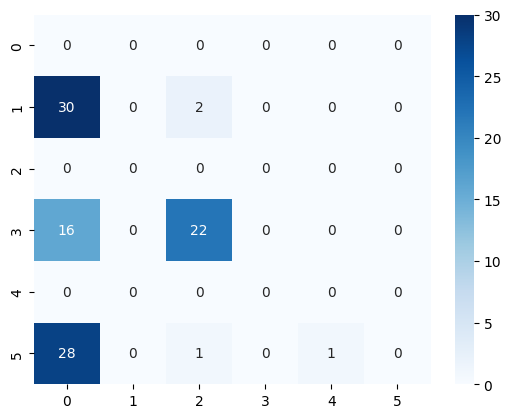
[48]:
pred_targets
[48]:
[['neutra'],
[''],
[''],
[''],
['positiva'],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
['neutra'],
['neutra'],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
['neutra'],
[''],
[''],
['neutra'],
[''],
['neutra'],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
['neutra'],
[''],
['neutra'],
['neutra'],
['neutra'],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
['neutra'],
['neutra'],
[''],
[''],
['neutra'],
[''],
['neutra']]
Prueba 3#
[50]:
prompt = """
TEMPLATE:
"Necesito que me ayudes en una tarea de clasificación de texto.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
""
PROMPT_LABELS:
""
PROMPT_DETAIL:
""
CHAIN_THOUGHT:
""
ANSWER_FORMAT:
""
"""
[52]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="es",
model_name="text-davinci-003",
model_provider_name="openai",
model_provider_token=token,
prompt_domain="opiniones de productos",
prompt_labels=["positiva", "negativa", "neutra"],
selector_k=20,
)
model.task.prompt.read_prompt(prompt)
model.train(
examples=train_reviews,
annotations=train_targets,
)
pred_targets = model.predict(test_reviews)
pred_targets = [pred if len(pred) == 1 else [""] for pred in pred_targets]
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[52]:
<Axes: >
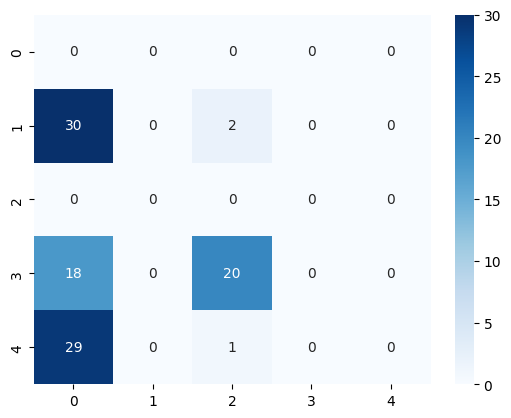
[53]:
pred_targets
[53]:
[['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
['neutra'],
['neutra'],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
['neutra'],
['neutra'],
[''],
[''],
[''],
['neutra'],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
['neutra'],
[''],
[''],
['neutra'],
['neutra'],
['neutra'],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
['neutra'],
[''],
[''],
[''],
[''],
[''],
['neutra'],
[''],
[''],
[''],
['neutra'],
[''],
['neutra'],
[''],
[''],
['neutra'],
[''],
['neutra']]
Conclusiones#
Parece que con el modelo Flan-t5-small, el mejor resultado se obtiene añadiendo más ejemplot y quitando la instrucción del prompt
Parece que hay mucho errores asociados con que la respuesta tenga un espacio antes de laa respuesta