Sentiment Analysis#
In this notebook we are going to use the Amazon Review Dataset to test Promptmeteo in the sentiment analysis task
1. Data Preparation - EN - Build sentiment dataset.#
The dataset contains reviews from Amazon in English collected between November 1, 2015 and November 1, 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID and the coarse-grained product category (e.g. ‘books’, ‘appliances’, etc.). The corpus is balanced across stars, so each star rating constitutes 20% of the reviews in each language.
[1]:
import polars as pl
data = pl.read_parquet("../data/amazon_reviews_en/amazon_reviews_multi-test.parquet")
data.head()
[1]:
| review_id | product_id | reviewer_id | stars | review_body | review_title | language | product_category |
|---|---|---|---|---|---|---|---|
| str | str | str | i32 | str | str | str | str |
| "en_0199937" | "product_en_090… | "reviewer_en_00… | 1 | "These are AWFU… | "Don’t waste yo… | "en" | "apparel" |
| "en_0863335" | "product_en_034… | "reviewer_en_06… | 1 | "I bought 4 and… | "One Star" | "en" | "other" |
| "en_0565010" | "product_en_035… | "reviewer_en_09… | 1 | "On first use i… | "Totally useles… | "en" | "other" |
| "en_0963290" | "product_en_058… | "reviewer_en_02… | 1 | "You want an HO… | "Gold filled ea… | "en" | "jewelry" |
| "en_0238156" | "product_en_048… | "reviewer_en_05… | 1 | "The glue works… | "Poor container… | "en" | "industrial_sup… |
For building a sentiment analysis dataset with the dataset we create the target using the variable stars. We supone that the reviews with low stars rate are related with negative sentiment and those with high starts rate are related with positive sentiment.
[2]:
sql = pl.SQLContext()
sql.register("data", data)
sentiment_data = (
sql.execute("""
SELECT
review_body as REVIEW,
CASE
WHEN stars=1 THEN 'negative'
WHEN stars=3 THEN 'neutral'
WHEN stars=5 THEN 'positive'
ELSE null
END AS TARGET,
FROM data
WHERE stars!=2 AND stars!=4;
""")
.collect()
.sample(fraction=1.0, shuffle=True, seed=0)
)
sentiment_data.head()
[2]:
| REVIEW | TARGET |
|---|---|
| str | str |
| "I reuse my Nes… | "positive" |
| "Fits great kin… | "positive" |
| "Movie freezes … | "negative" |
| "This is my thi… | "positive" |
| "For the money,… | "neutral" |
2.1. Classification - EN - Model text-davinci-003#
2.1.1 Instanciate Model#
[3]:
import sys
sys.path.append("..")
from promptmeteo import DocumentClassifier
model = DocumentClassifier(
language="en",
model_name="gpt-3.5-turbo-instruct",
model_provider_name="openai",
model_provider_token="sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", # OPENAI TOKEN
)
2.1.2 Classification Prompt template#
Promptmeteo has predefined prompt templates for each of the availables languages, models and tasks. This allows the user not to wonder about defining the prefect prompt but rather, to parametrize the prompt with the parameters of the use case. For the document classification task in english with OpenAI, the prompt template is:
[4]:
print(model.task.prompt.PROMPT_EXAMPLE)
# Copyright (c) 2023 Paradigma Digital S.L.
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
TEMPLATE:
"I need you to help me with a text classification task.
{__PROMPT_DOMAIN__}
{__PROMPT_LABELS__}
{__SHOT_EXAMPLES__}
{__CHAIN_THOUGHT__}
{__ANSWER_FORMAT__}"
PROMPT_DOMAIN:
"The texts you will be processing are from the {__DOMAIN__} domain."
PROMPT_LABELS:
"I want you to classify the texts into one of the following categories:
{__LABELS__}."
PROMPT_DETAIL:
""
SHOT_EXAMPLES:
"{__EXAMPLES__}"
CHAIN_THOUGHT:
"Please provide a step-by-step argument for your answer, explain why you
believe your final choice is justified, and make sure to conclude your
explanation with the name of the class you have selected as the correct
one, in lowercase and without punctuation."
ANSWER_FORMAT:
"In your response, include only the name of the class as a single word, in
lowercase, without punctuation, and without adding any other statements or
words."
2.1.3 Train the model#
The training process create a vector database in memory with FAISS, the main advantage of using this king of vector database is that it is serializable to a file and be stored in disk, which allows us to save the vectors training process as a model artifact
[5]:
train_reviews = sentiment_data.head(100).select("REVIEW").to_series().to_list()
train_targets = sentiment_data.head(100).select("TARGET").to_series().to_list()
model = model.train(examples=train_reviews, annotations=train_targets)
2.1.4 Predict new data#
[6]:
import seaborn as sns
from sklearn.metrics import confusion_matrix
test_reviews = sentiment_data.head(100).select("REVIEW").to_series().to_list()
test_targets = sentiment_data.head(100).select("TARGET").to_series().to_list()
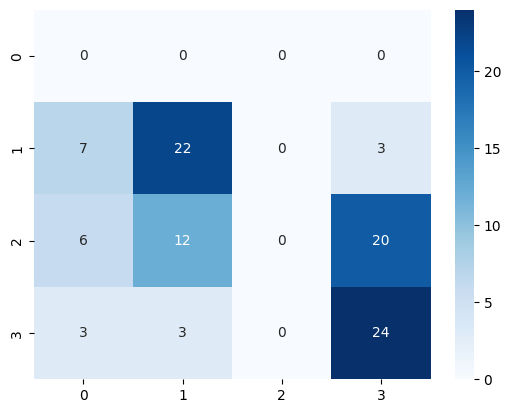
pred_targets = model.predict(test_reviews)
sns.heatmap(
confusion_matrix(test_targets, [i[0] for i in pred_targets]),
annot=True,
cmap="Blues",
)
[6]:
<Axes: >
2.2. Classification - EN - Model Flan-T5-XXL#
2.2.1 Results#
[17]:
model = DocumentClassifier(
language="en",
model_name="google/flan-t5-xxl",
model_provider_name="hf_hub_api",
model_provider_token="hf_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", # HF API TOKEN
)
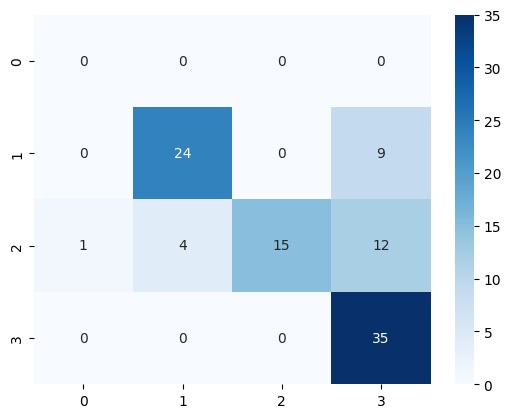
model = model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[17]:
<Axes: >
2.3. Classification - EN - Falcon-7b-instruct#
2.3.1 Results#
[4]:
model = DocumentClassifier(
language="en",
model_name="tiiuae/falcon-7b-instruct",
model_provider_name="hf_hub_api",
model_provider_token="hf_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", # HF API TOKEN
)
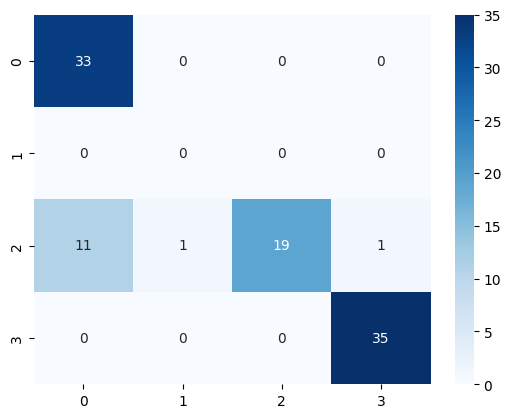
model = model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
You're using a different task than the one specified in the repository. Be sure to know what you're doing :)
[4]:
<Axes: >
2.4. Classification - EN - Model Flan-t5-small#
2.4.1 Results#
[29]:
model = DocumentClassifier(
language="en",
model_name="google/flan-t5-small",
model_provider_name="hf_pipeline",
)
model = model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
Token indices sequence length is longer than the specified maximum sequence length for this model (603 > 512). Running this sequence through the model will result in indexing errors
/opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:1270: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
warnings.warn(
[29]:
<Axes: >
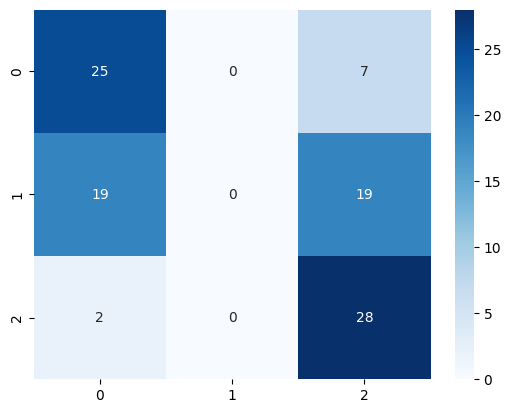
3. Data Preparation - SP - Build sentiment dataset.#
[7]:
import polars as pl
data = pl.read_parquet("../data/amazon_reviews_sp/amazon_reviews_multi-test.parquet")
data.head()
sql = pl.SQLContext()
sql.register("data", data)
sentiment_data = (
sql.execute("""
SELECT
review_body as REVIEW,
CASE
WHEN stars=1 THEN 'negative'
WHEN stars=3 THEN 'neutral'
WHEN stars=5 THEN 'positive'
ELSE null
END AS TARGET,
FROM data
WHERE stars!=2 AND stars!=4;
""")
.collect()
.sample(fraction=1.0, shuffle=True, seed=0)
)
sentiment_data.head()
[7]:
| REVIEW | TARGET |
|---|---|
| str | str |
| "El filtro de d… | "positive" |
| "Un poquito esc… | "positive" |
| "Para qué decir… | "negative" |
| "Mi hija esta e… | "positive" |
| "Se podría mejo… | "neutral" |
[8]:
train_reviews = sentiment_data.head(100).select("REVIEW").to_series().to_list()
train_targets = sentiment_data.head(100).select("TARGET").to_series().to_list()
test_reviews = sentiment_data.tail(100).select("REVIEW").to_series().to_list()
test_targets = sentiment_data.tail(100).select("TARGET").to_series().to_list()
4.1 Classification - SP - Model text-davinci-003#
4.1.1 Results#
[9]:
model = DocumentClassifier(
language="en",
model_name="gpt-3.5-turbo-instruct",
model_provider_name="openai",
model_provider_token="sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", # OPENAI TOKEN
)
model = model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(
confusion_matrix(test_targets, [i[0] for i in pred_targets]),
annot=True,
cmap="Blues",
)
[9]:
<Axes: >
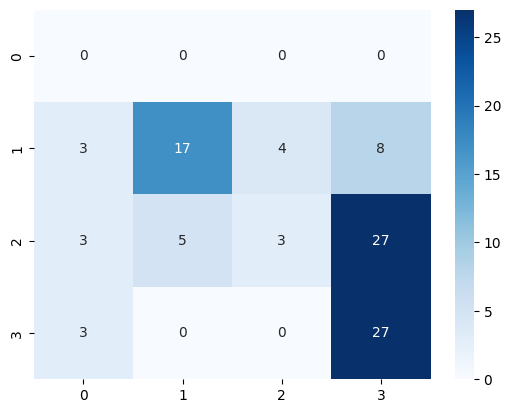
4.2 Classificaction - SP - Flan-t5-small#
4.2.1 Results#
[32]:
model = DocumentClassifier(
language="es",
model_name="google/flan-t5-small",
model_provider_name="hf_pipeline",
)
model = model.train(examples=train_reviews, annotations=train_targets)
pred_targets = model.predict(test_reviews)
sns.heatmap(confusion_matrix(test_targets, pred_targets), annot=True, cmap="Blues")
[32]:
<Axes: >